Introducing LogSlash and the End of Traditional Logging

LogSlash is a new standard method that doubles the efficiency and value of existing log platforms by doubling capacity and cutting logging costs in half. It does this by performing a time-window-based, intelligent reduction of logs in transit. LogSlash was created by John Althouse, who led the creation of standard methods like JA3/S and JARM that are built into many vendor products, including AWS, Google, Azure, and used by the Fortune 500.
This blog post introduces LogSlash, the method, benefits, and requirements. For more technical details, please visit our GitHub.
LogSlash is free for internal business use and is available here: https://github.com/FoxIO-LLC/LogSlash

The Too-Many-Logs Problem
Data logging is a foundational capability for all organizations. Logs are used in Machine Learning (ML) and Artificial Intelligence (AI) algorithms to track activity of interest and are critical for understanding the performance, availability, and security of the world’s infrastructure. As such, organizations tend to want to log everything, and rightfully so. Security Operators, for example, don’t want to miss potentially malicious activity. For various reasons they may also need to search across those logs going back several years. The solutions to date for processing and storing all of these logs have essentially been, ‘put the Big Data into a Data Lake or Data Warehouse and run searches and algorithms against it.’ This has led the world to spend ~$215 billion on logging infrastructure, licensing, power, and space in 2021, according to Statista. But what if we could cut that number in half?
Most organizations suffer from a too-many-logs problem where the cost of logging is straining budgets. The primary costs behind logging infrastructures are log ingestion and log processing/search, both in compute and licensing. Some log management licensing is based on the overall compute required, while others are based on log ingest volume. In either case, fewer logs equals less licensing costs as less compute is required to ingest, index, process, and search across the remaining logs. So how do we get less logs without losing valuable data?
The ultimate point of logging data is to understand what happened. In our quest to understand what happened, we tend to log and store everything. And it’s important to remember that in a work environment, both humans and systems tend to do the same process, over and over again. If a system does something 1,000 times in one minute, such as a load balancer connecting to an application server, do we really need to process, store, and search across 1,000 log lines that say the same thing? What if instead, we just process, store, and search across one log line that says this thing happened 1,000 times within a one-minute window? Both methods tell the same story of what happened and they both have the same value, but the latter is exceedingly more efficient to process, store, and run searches/algorithms against.
The LogSlash Method
LogSlash is a method for the reduction of log volume without sacrificing analytical capability. It can sit between your log producers (e.g, firewalls, systems, applications) and your existing log platform (e.g., Splunk, Databricks, Snowflake, S3). No need to change your logging infrastructure as this is designed to slot into any existing setup.
With LogSlash, 10TB/day of logs flowing into Splunk can be reduced to 5TB/day without any loss to the value of the logs. LogSlash does this by performing a time-window based consolidation of similar logs using configurable transforms to retain what’s valuable to you.
As an example, Bob connects to Gmail and starts clicking through his emails. While going through the emails, he clicks a malicious link.
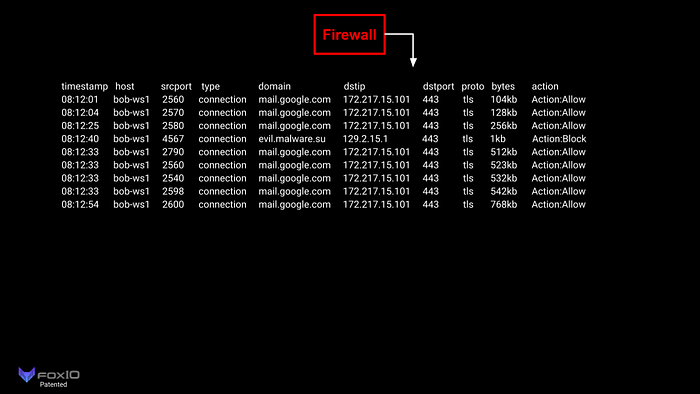
These logs then flow through the LogSlash method before ingest into the logging platform following this logical configuration:
timewindow = 60s
Group\_by = \[ host, type, domain, dstip, dstport, proto, action \]
Fields\_ignored = srcport
Fields\_concatinated =
Fields\_sum = bytes
The output fields now include “timestamp-end”, “bytes-total” and “logslash,” which shows how many times the particular event occurred. We’re ignoring all but the first srcport as that field holds little analytical value. If we wanted to retain each srcport, we could configure LogSlash to concatenate them with a comma delimiter instead.
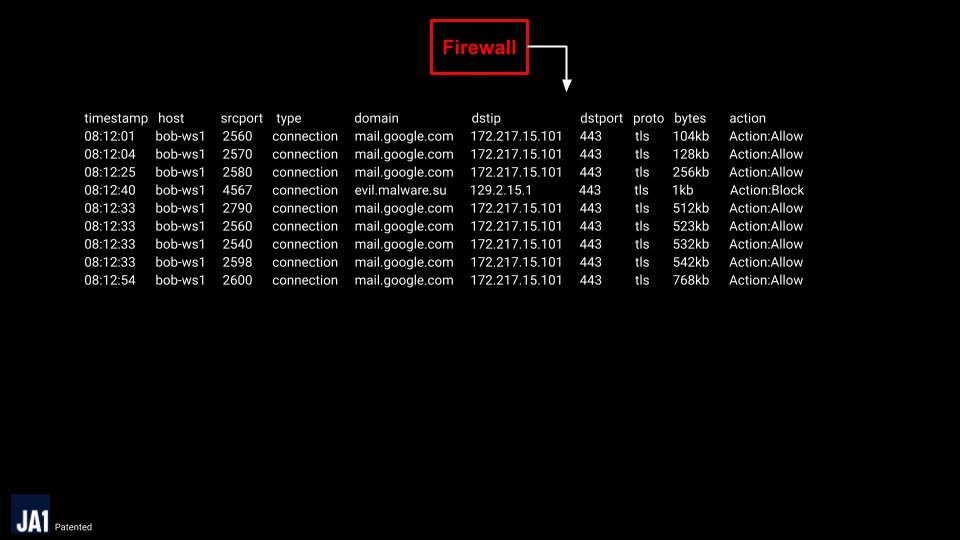
In this simplified example, we can see that Bob connected to Gmail 8 times over TLS/443 within a 53-second window with a total byte count of 3365kb and also attempted to connect to a malicious site once. LogSlash reduced the logs flowing into the log platform by 78% without any loss to the understanding of what happened. This can significantly reduce the cost to index, store, and process/search against log data, as well as reduce log platform licensing costs.
In testing LogSlash with a one-minute time window on AWS VPC Flow logs using normal corporate internet traffic, we found that on average, LogSlash reduced VPC Flow logs by 50%. In a production environment where the same systems are communicating to the same systems thousands of times a minute, such as load balancers communicating to application servers, LogSlash can reduce logs by as much as 95%, on average, without reducing the value of the logs.
In testing LogSlash with Zeek log data from corporate internet traffic, we found a reduction of 38% in SSL logs, 63% in Conn logs, 83% in DNS logs, 91% in HTTP logs, and 93% in File logs. The large delta between the savings with SSL logs and HTTP logs is due to SSL logging each connection which can persist for minutes whereas HTTP logs each transaction. It is transaction-based logging (e.g. application logs, S3 access logs) which can see massive savings with LogSlash.
For logs with unique identifiers (GUIDs), like in AWS CloudTrail, LogSlash can be configured to ignore all but the first GUID in a set of similar logs. This maintains a GUID to identify the set of events which can still be used as a primary key for log retrieval. Shared GUIDs hold a little more analytical value for pivoting between log types and can be concatenated if there are no other shared pivot points which depend on the log type. In either case, LogSlash still provides significant savings without sacrificing analytical capability.
Using LogSlash with other Log Reduction Methods
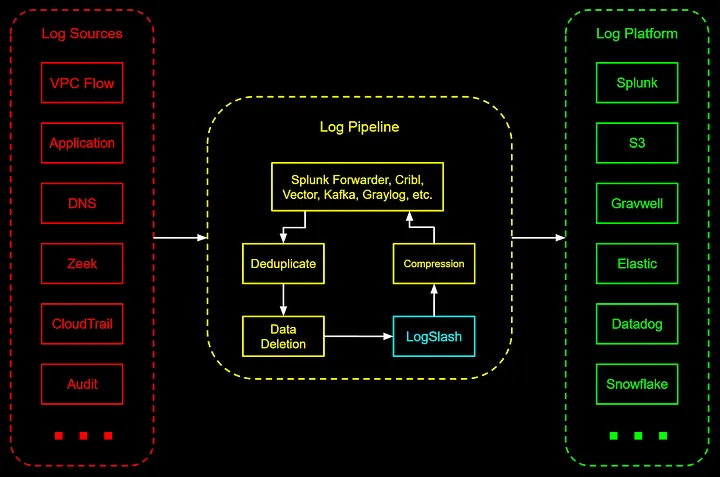
LogSlash is designed to work with other common log reduction methods such as standard compression, data deletion, and deduplication.
Deduplication. Deduplication is needed when you have a system that tends to log the exact same thing multiple times in a row. LogSlash is designed to reduce similar logs down to a single log without any loss to the value of what happened. LogSlash should be performed after deduplication and data deletion methods have already been performed.
Data Deletion. There are a number of technologies that facilitate removing erroneous data from logs before being passed off to their destination, such as removing the bloated Description field from Windows Event Logs. LogSlash provides significant savings on top of these standard data deletion methods.
Compression. ASCII compression tools like Gzip are used to losslessly compress logs for cheaper storage. When a search is performed against these logs, they are uncompressed and each log line is passed through the processor. Sending logs through LogSlash and then compressing the output significantly reduces log file size on disk compared to solely using compression. LogSlash also significantly reduces the compute and RAM required to uncompress and search across logs, as fewer bits are being passed through the processor at read time.
Implementing LogSlash
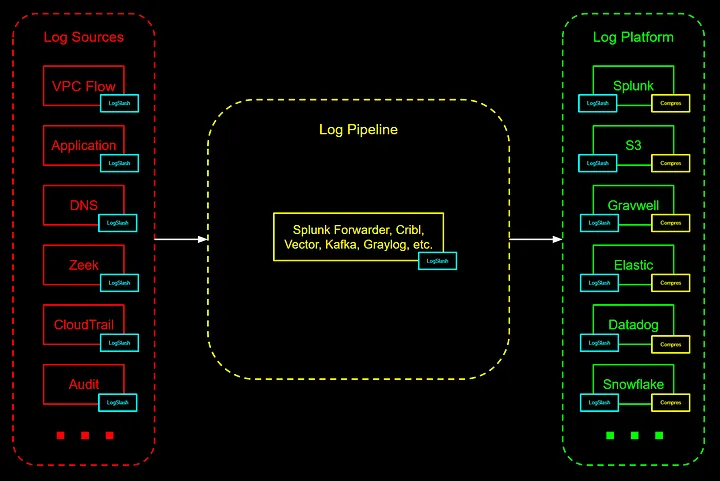
LogSlash was designed as a method that could be easily implemented into existing logging technologies and tools that you’re using today. Much like how JA3 was originally released as a Zeek Script before being implemented into vendor technologies, we are releasing LogSlash as Vector scripts. Vector is an open-source, lightweight, ultra-fast logging pipeline tool that contains the functions necessary to support LogSlash. We will soon be releasing LogSlash as Kafka Streams scripts and Cribl packs as well.
Much like log normalization, LogSlash requires a separate configuration for each log type so you can specify what fields are important and what fields can be transformed or ignored. As such, these configs can be built as part of the normalization development process. We are developing and releasing LogSlash scripts that can either be used directly or as templates for your own use cases.
LogSlash could also be implemented directly into the log source. As an example, S3 Audit logs in AWS could have an option to LogSlash before storing. Using LogSlash as a built-in option, developed by that technology’s team, would allow organizations to log what they otherwise potentially couldn’t afford, and at no extra effort to their observability teams.
In order for LogSlash to seamlessly integrate with log platforms, graphing tools, and anything else that relies on counting log lines to produce graphs and totals, those tools will need to be aware of LogSlash. For example, if you run a timechart function on Splunk against LogSlashed logs, it would require some fancy SPL’ing to output the correct graph because Splunk does not yet natively multiply or divide the amount of field values by the logslash value. Fortunately, adding support for handling LogSlashed logs is fairly straight-forward. Fast moving upstarts in log analysis, like Gravwell, have stated LogSlash support will be available in their next release cycle. We look forward to seeing many organizations benefit from dramatically reduced log data as more tools add LogSlash support in the coming months.
Future Development
While LogSlash is currently a set of simple scripts with a separate script for each log type, we’re working on a system that will adaptively recognize data types, so it can intelligently apply the appropriate LogSlash functions universally. This system will make it easy to onboard different log types with an initial configuration that can be tweaked. Logs will be LogSlashed on a rolling one-minute window by default, but this window will be configurable with potential savings dynamically displayed along with sample outputs.
Conclusion
LogSlash is a new standard method for the reduction of log volume without reducing log value and is designed to be implemented into existing technologies and logging pipelines. It’s a much more efficient approach to traditional logging. Essentially, why log, store, and search across 1,000 log lines that say the same thing when we can log, store and search across 1 log line that says the thing happened 1,000x? LogSlash significantly reduces compute and storage requirements and has the potential to double the value of log platforms that support it. Initially being released as a set of Vector scripts, we will soon be providing LogSlash as Kafka Streams and Cribl Packs and are working toward direct integration in logging pipeline and platform tools.
LogSlash is available here: https://github.com/FoxIO-LLC/LogSlash
LogSlash was created by John Althouse
LogSlash is patented by FoxIO, LLC — Patent US 10,877,972
Please reach out to us if you have any questions or have interest in commercial vendor licensing.
We are really excited to also share our new, innovative software license with the industry! We worked with renowned Open Source License expert Heather Meeker, along with legal professors and licensing lawyers, to create the FoxIO License. It is similar to the intention behind the Nmap Public Source License, while being only 2 pages, human readable, and reusable. Those familiar with licensing know that it takes a lot of expertise and time to create small, readable licenses. A lot of care and effort went into this. The FoxIO License is free to use for your own projects. Read more about it in an upcoming blog post!